如果只写怎么抓取网页,肯定会被吐槽太水,满足不了读者的逼格要求,所以本文会通过不断的审视代码,做到令自己满意(撸码也要不断迸发新想法!
本文目标:抓取什么值得买网站国内优惠的最新商品,并且作为对象输出出来,方便后续入库等操作
抓取常用到的npm模块
本文就介绍两个:request 和 cheerio,另外lodash是个工具库,不做介绍,后面篇幅会继续介绍其他用到的npm库。
- request:是一个http请求库,封装了很多常用的配置,而且也有promise版本(还有next版本。
- cheerio:是一个类似jQuery的库,可以将html String转成类似jQ的对象,增加jQ的操作方法(实际是htmlparser2
request 示例
var request = require('request');
request('http://www.smzdm.com/youhui/', (err, req)=>{
if(!err){
console.log(Object.keys(req))
}
})
通过上面的代码就看到req实际是个response对象,包括headers 、statusCode、body 等,我们用body就是网站的html内容
cheerio 示例
var request = require('request')
var cheerio = require('cheerio')
cheerio.prototype.removeTagText = function () {
var html = this.html()
return html.replace(/<([\w\d]+)\b[^<]+?<\/\1>/g, (m) => {
return ''
})
}
request('http://www.smzdm.com/youhui/', (err, req) => {
if (!err) {
var body = req.body
var $ = cheerio.load(body, {
decodeEntities: false
})
$('.list.list_preferential').each((i, item) => {
var $title = $('.itemName a', item)
var url = $title.attr('href')
var title = $title.removeTagText().trim()
var hl = $title.children().text().trim()
var img = $('img', item).attr('src')
var desc = $('.lrInfo', item).html().trim()
desc = desc.replace(/<a\b.+?>阅读全文<\/a>/g, '')
var mall = $('.botPart a.mall', item).text().trim()
console.log({title, hl, url, img, desc, mall})
})
}
})
简单解释下,removeTagText是直接扩展了cheerio的一个方法,目的是去掉类似
再特价:QuanU 全友 布艺沙发组合<span class="z-highlight">2798元包邮(需定金99元,3.1付尾款)</span>
里面span之后的文字。执行后得到下面的结果:

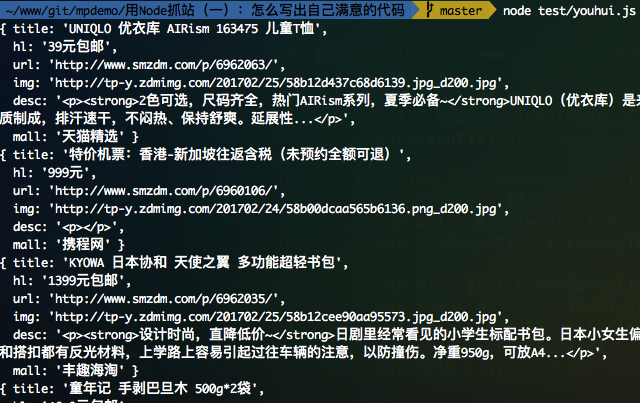
怎么写出自己满意的代码
从上面需求来看,只需要提取列表页面的商品信息,而取到数据之后,使用cheerio进行了解析,然后通过一些「选择器」对数据进行「提取加工」,得到想要的数据。
重点是选择器 和 提取加工,如果想要的字段多了,那么代码会越写越多,维护困难,最重要的是「不环保」,今天抓什么值得买,明天抓惠惠网,代码还要copy一份改一改!一来二去,抓的越多,那么代码越乱,想想哪天不用request了,是不是要挨个修改呢?所以要抓重点,从最后需要的数据结构入手,关注选择器 和 提取加工。
handlerMap
从最后需要的数据结构入手,关注选择器 和 提取加工。我设计一种对象结构,作为参数传入,这个参数我起名:handlerMap,最后实现一个spider的函数,用法如下:
spider(url, callback, handlerMap)
从目标数据结构出发,最后数据什么样子,那么handlerMap结构就是什么样子,key就是最后输出数据的key,是由selector和handler两个key组成的对象,类似我们需要最后产出的数据是:
[{
title: '',
ht: '',
url: '',
img: '',
mall: '',
desc: ''
}, {item2..}...]
那么需要的handlerMap就是:
{
title: {
selector: '.itemName a',
handler: 'removeTagText'
},
ht: {
selector: '.itemName a span',
handler: 'text'
},
url: {
selector: '.itemName a',
handler: 'atrr:href'
},
img: {
selector: 'img',
handler: 'attr:src'
},
mall: {
selector: '.botPart a.mall',
handler: 'text'
},
desc: {
selector: '.lrInfo',
handler: function (data){
return data.replace(/<a\b.+?>阅读全文<\/a>/g, '')
}
}
}
再酷一点,就是简写方法:url:".itemName a!attr:href”,另外再加上如果抓取的是JSON数据,也要一起处理的情况。经过分析之后,开始改造代码,代码最后分为了两个模块:
spider.js:包装request 模块,负责抓取页面将页面交给parser.js解析出来想要的数据parser.js:负责解析handlerMap,同时支持json和html两种类型的页面进行解析
虽然增加不少代码工作量,但是抽象后的代码在使用的时候就更加方便了,自己还是别人在使用的时候,不用关心代码实现,只需要关注抓取的页面url、要提取的页面内容和数据得到后的继续操作即可,使用起来要比之前混杂在一起的代码更加清晰简洁;并且抓取任意页面都不需要动核心的代码,只需要填写前面提到的handlerMap。
总结
其实Node抓取页面很简单,本文只是通过一个简单的抓取任务,不断深入思考,进行抽象,写出自己满意的代码,以小见大,希望本文对读者有所启发😄
今天到此结束,完成一个基础抓取的库,有空继续介绍Node抓站的知识,欢迎大家交流讨论
本文的完整代码,在github/ksky521/mpdemo/ 对应文章名文件夹下可以找到