抓取如果抓取的太快太频繁会被源站封IP,本文会介绍下通过限流、限速和使用代理的方式来防止被封
上篇文章,抓取「电影天堂」最新的170部电影,在抓取首页电影list之后,会同时发出170个请求抓取电影的详情页,这样在固定时间点集中爆发式的访问页面,很容易在日志中被找出来,而且并发请求大了,很可能会中网站的防火墙之类的策略,IP被加到黑名单就悲剧了
限流&限速
先说下限流的方法,将批量的并发请求,分成多次固定请求个数,等上一次抓取结束后,再开始下一次抓取,直到全部抓取结束。
这里我使用async模块限制并发次数,async主要有:集合、流程和工具三大类方法,这里我使用eachLimit(arr, limit, iterator, [callback]),所有修改是上篇文章的fetchContents方法,该方法接受抓取到的170个文章的url list,这次通过eachLimit将170个url按照3个一组并发,依次执行,具体代码如下:
function fetchContents (urls) {
return new Promise((resolve, reject) => {
var results = []
async.eachLimit(urls, 3, (url, callback) => {
spider({url: url, decoding: 'gb2312'}, {
url: {
selector: '#Zoom table td a!text'
},
title: {
selector: '.title_all h1!text'
}
}).then((d) => {
results.push(d)
callback()
}, () => {
callback()
})
}, () => {
resolve(results)
})
})
}
限流只是控制了一次并发的请求数,并没有让抓取程序慢下来,所以还需要限速,在限流的基础上限速就变得很简单,只需要在执行eachLimit的callback的时候,加上个Timer就好了,为了方便查看限速的效果,每次抓取成功之后,都console.log显示时间,所以改完的代码如下:
function fetchContents (urls) {
return new Promise((resolve, reject) => {
var results = []
async.eachLimit(urls, 3, (url, callback) => {
spider({url: url, decoding: 'gb2312'}, {
url: {
selector: '#Zoom table td a!text'
},
title: {
selector: '.title_all h1!text'
}
}).then((d) => {
var time = moment().format(‘HH:MM:ss')
console.log(`${url}===>success, ${time}`)
results.push(d)
setTimeout(callback, 2e3)
}, () => {
callback()
})
}, () => {
resolve(results)
})
})
}
效果如下:
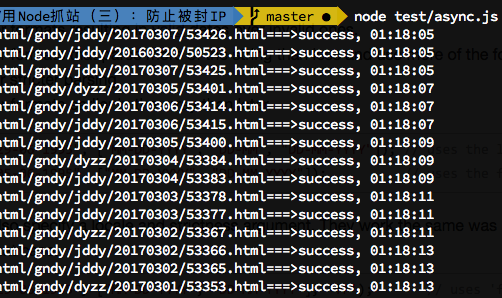
避免重复抓取
因为一些网站更新比较慢,我们写的抓取程序在定时脚本任务(crontab)跑的时候,可能网站还没有更新,如果不做处理会造成资源的浪费,尤其国内不少VPS都是有流量限制的,不做控制,真金白银就打水漂了。。
继续拿「电影天堂」最新更新的内容进行抓取,如果假设每五分钟执行一次抓取脚本,那么需要记录下已经抓取过的文章(电影),这里我简单处理一下,通过一个_fetchedList.json的文件,记录抓取完的文章(电影)。具体思路如下:
- 抓取每个电影详情页成功后,将抓取到的url放入一个数组Array
- 等全部抓取结束,将这个数组Array,写到文件
_fetchedList.json - 下次抓取的时候,require这个
_fetchedList.json,得到数组Array,抓取之前判断要抓取的url是否在这个数组内 - 数组保持长度是300(170个电影够用了),保证先入先出,即超过300长度将最早的移出
具体代码讲解如下:
引入抓取的记录文件
var fs = require('fs-extra')
var path = require('path')
var uniqueArray = []
const UNIQUE_ARRAY_URL = './_fetchedList.json'
try {
uniqueArray = require(UNIQUE_ARRAY_URL)
} catch (e) {
}
改造url处理函数,过滤下url数组,已经抓取过的就不要抓取了
function dealListData (data) {
return new Promise((resolve, reject) => {
var urls = _.get(data, 'items')
if (urls) {
urls = urls.map(url => {
return 'http://www.dytt8.net' + url
}).filter(url => {
return uniqueArray.indexOf(url) === -1
})
// 如果为空就reject
urls.length ? resolve(urls) : reject('empty urls')
} else {
reject(urls)
}
})
}
增加一个处理方法,保持uniqueArray长度是300,不要无限增加
function addUniqueArray (url) {
uniqueArray.push(url)
if (uniqueArray.length > 300) {
// 超长就删掉多余的
uniqueArray.shift()
}
}
在抓取完之后,记录新的uniqueArray数组内容到json文件:
fetchList().then(dealListData).then(fetchContents).then((d) => {
console.log(d, d.length)
// json落地
fs.writeJson(path.join(__dirname, UNIQUE_ARRAY_URL), uniqueArray)
}).catch((e) => {
console.log(e)
})
代理
为了迷惑被抓取的网站,除了伪装User-Agent等方法,最重要的是使用代理服务,如果有钱的主可以买代理,然后用,对于我们做demo,那就直接抓取代理吧!下面代码是抓取快代理网站的代理代码:
var spider = require('../lib/spider')
function fetchProxy () {
return spider({
url: 'http://www.kuaidaili.com/proxylist/1/'
}, {
selector: '#index_free_list tbody tr',
handler: function ($tr, $) {
var proxy = []
$tr.find('td').each(function (i) {
proxy[i] = $(this).html().trim()
})
if (proxy[0] && proxy[1] && /\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}/.test(proxy[0]) && /\d{2,6}/.test(proxy[1])) {
} else {
// console.log(proxy);
}
return proxy
}
})
}
fetchProxy().then(data => {
console.log(data.map(p => p.join(',')))
})
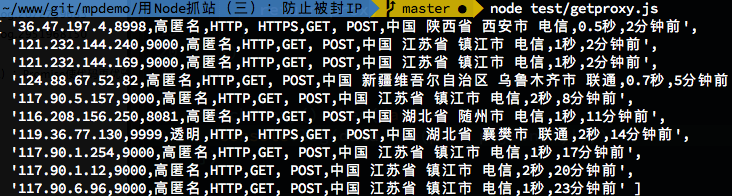

抓取之后的代理不一定直接就可以用,还需要测试下代理是否可以访问成功我们要抓取的网站,先写个checkProxy(proxy)的方法,用于检测使用传入的proxy是否抓取成功:
function checkProxy (proxy) {
return spider({
url: 'http://www.dytt8.net/index.htm',
proxy: proxy,
timeout: 5e3,
decoding: 'gb2312'
}, {
items: {
selector: '.co_area2 .co_content2 ul a!attr:href'
}
})
}
然后将从快代理网站抓取到的代理一次传入进去:
fetchProxy().then(data => {
var len = data.length
var succArray = []
data.forEach(p => {
checkProxy(`http://${p[0]}:${p[1]}`).then(() => {
succArray.push(p)
}).finally(done).catch(e => void (e))
})
function done () {
len--
if (len === 0) {
console.log(succArray)
}
}
})
这里最后console.log出来的就是通过代理抓取成功的代理,可以存入到数据库,以后抓取使用。
代理的维护
最后在简单说下代理的维护,抓取到了代理,因为是免费的,一般过一段时间就会不能用了,所以在使用的时候,可以将代理放到一个数据库中维护,数据库中有字段:succCount和failCount 用于记录每次使用该代理成功和失败的次数。每次使用代理抓取的时候,要有个反馈机制,如果成功就succCount +1 ,失败就failCount +1。当失败次数过多的时候,这个代理就不要再使用了。
后语
本系列写到第三篇了,后面还会有一些常见问题解答。周末看到一篇用Python抓知乎导出txt或者markdown的文章,以后手痒就会放出番外篇 😁