抓取如果抓取的太快太频繁会被源站封IP,本文会介绍下通过限流、限速和使用代理的方式来防止被封
上篇文章,抓取「电影天堂」最新的170部电影,在抓取首页电影list之后,会同时发出170个请求抓取电影的详情页,这样在固定时间点集中爆发式的访问页面,很容易在日志中被找出来,而且并发请求大了,很可能会中网站的防火墙之类的策略,IP被加到黑名单就悲剧了
限流&限速
先说下限流的方法,将批量的并发请求,分成多次固定请求个数,等上一次抓取结束后,再开始下一次抓取,直到全部抓取结束。
这里我使用async模块限制并发次数,async主要有:集合、流程和工具三大类方法,这里我使用eachLimit(arr, limit, iterator, [callback]),所有修改是上篇文章的fetchContents方法,该方法接受抓取到的170个文章的url list,这次通过eachLimit将170个url按照3个一组并发,依次执行,具体代码如下:
function fetchContents (urls) {
return new Promise((resolve, reject) => {
var results = []
async.eachLimit(urls, 3, (url, callback) => {
spider({url: url, decoding: 'gb2312'}, {
url: {
selector: '#Zoom table td a!text'
},
title: {
selector: '.title_all h1!text'
}
}).then((d) => {
results.push(d)
callback()
}, () => {
callback()
})
}, () => {
resolve(results)
})
})
}
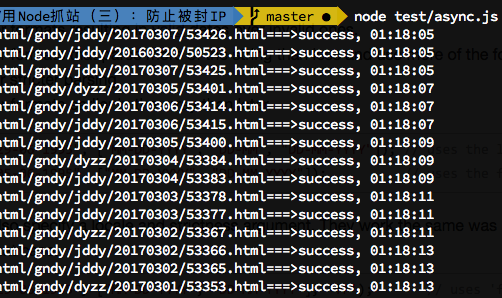
限流只是控制了一次并发的请求数,并没有让抓取程序慢下来,所以还需要限速,在限流的基础上限速就变得很简单,只需要在执行eachLimit的callback的时候,加上个Timer就好了,为了方便查看限速的效果,每次抓取成功之后,都console.log显示时间,所以改完的代码如下:
function fetchContents (urls) {
return new Promise((resolve, reject) => {
var results = []
async.eachLimit(urls, 3, (url, callback) => {
spider({url: url, decoding: 'gb2312'}, {
url: {
selector: '#Zoom table td a!text'
},
title: {
selector: '.title_all h1!text'
}
}).then((d) => {
var time = moment().format(‘HH:MM:ss')
console.log(`${url}===>success, ${time}`)
results.push(d)
setTimeout(callback, 2e3)
}, () => {
callback()
})
}, () => {
resolve(results)
})
})
}
效果如下:
避免重复抓取
因为一些网站更新比较慢,我们写的抓取程序在定时脚本任务(crontab)跑的时候,可能网站还没有更新,如果不做处理会造成资源的浪费,尤其国内不少VPS都是有流量限制的,不做控制,真金白银就打水漂了。。